In this article, I’ll try to share my knowledge and concept of Clean Architecture and how to apply it properly in systems.
What is Good Design?
Software is well designed if the measure of effort required to fulfill the demands of the customers is low and stays low throughout the lifetime of the system. The effort refers to the human resources who are dedicated to up and running the required system. If the efforts grow with each release, the design is bad.
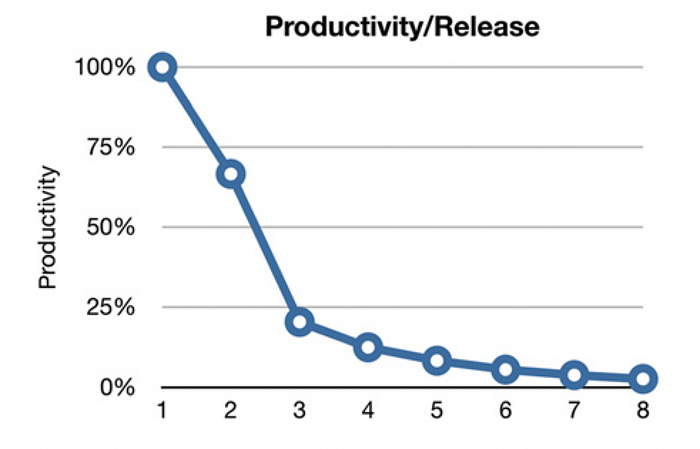
The figure depicts the signature of a mess in a system to the developers. Productivity of the developers was at pick during the first release but their productivity degraded with each release. Most modern developers have a misconception: “We can clean it up later; we just have to get to market fast!”. Writing messy codes makes them go fast in short term but just slows them in the long run. According to Uncle Bob, the simple truth of software development:
The only way to go fast, is to go well.
What is Architecture?
“The architecture of a software system is the shape given to that system by those who build it. The form of that shape is in the division of that system into components, the arrangement of those components, and the ways in which those components communicate with each other.” – excerpt from Clean Architecture: A Craftsman’s Guide to Software Structure and Design (Robert C. Martin Series)
Every software system incorporates two types of value: behavior and structure. The second of them is the greatest of the two because it is the value that makes software soft. The software was invented to easily change the behavior of machines. But that flexibility depends critically on the shape of the system, the arrangement of its components, and the way those components are interconnected. The primary purpose of a well-shaped architecture is to support the life cycle of the system. Good architecture makes the system easy to understand, easy to develop, easy to deploy, and easy to maintain. Moreover, it is to leave as many options as possible, for as long as possible. The main objective is to minimize the lifetime cost of the system and maximize programmer productivity.
Good architecture must support
- Use Cases – the intent of the system is the first priority of the architecture. The most important thing a good architecture can do to support behavior is to clarify and expose that behavior so that the intent of the system is visible at the architectural level.
- Operation – a good architecture of a system makes the operation including use cases, features, and the required behaviors of the system readily apparent to the developers. Architecture should reveal operation which simplifies the understanding of the system, and therefore, greatly aids in development and maintenance.
- Maintenance – The primary cost of maintenance is in spelunking and risk. Spelunking is the cost of digging through the existing software, trying to determine the best place and the best strategy to add a new feature or to repair a defect. While making such changes, the likelihood of creating inadvertent defects is always there, adding to the cost of risk. A carefully thought-through architecture vastly mitigates these costs by separating the system into components, and isolating those components through stable interfaces, it is possible to illuminate the pathways for future features and greatly reduce the risk of accidental breakage.
- Development – A system that must be developed by an organization with many teams and many concerns must have an architecture that facilitates independent actions by those teams so that the teams do not interfere with each other during development. This is accomplished by properly partitioning the system into well-isolated, independently developable components. Those components can then be allocated to teams that can work independently of each other.
- Deployment – A good architecture helps the system to be immediately deployable after build. A goal of a software architecture should be to make a system that can be easily deployed with a single action. This is achieved through the proper partitioning and isolation of the components of the system, including those master components that tie the whole system together and ensure that each component is properly started, integrated, and supervised.
- Leaving Options Open – A good architecture makes the system easy to change, in all the ways that it must change, by leaving options open. Balancing all of these concerns with a component structure that mutually satisfies them all is pretty hard in reality. However, some principles are relatively inexpensive to implement and can help to balance them by partitioning the systems into well-isolated components that allow us to leave as many options open as possible, for as long as possible.
What is Clean Architecture?
In 2012 Robert C. Martin proposed the architectural pattern in his famous book – “Clean Architecture: A Craftsman’s Guide to Software Structure and Design” by thinking about isolated, maintainable, testable, scalable, evolutive, and well-written code. Though there are a whole range of architectures e.g. Hexagonal Architecture, Onion Architecture, DCI, BCE, etc. having variations in their details, they have a similar objective which is the Separation of concerns. They all achieve this separation by dividing the software into layers. Each has at least one layer of business rules and another layer for user and system interfaces. Uncle Bob presented his architecture together with this diagram:

The key points of this architecture are –
- It is really about the separation of Concerns.
- Should be independent of frameworks. This allows you to use frameworks as tools rather than forcing you to cram your system into their limited constraints.
- Every layer should be testable. The business rules can be tested without the UI, database, web server, or any other external element.
- Should be independent of UI. The UI can change easily, without changing the rest of the system. A web UI could be replaced with a console UI, for example, without changing the business rules.
- Should be independent of the database. You can swap out Oracle or SQL Server for Mongo, BigTable, CouchDB, or something else. Your business rules are not bound to the database.
- Should be independent of any external agency. The innermost circle is the highest level. Inner circles are policies and other circles are mechanisms. Inner circles cannot depend on outer circles. Also, outer circles cannot influence inner circles.
Principles of clean architecture
Some of the following principles are shared with SOLID principles defined by Uncle Bob and other popular strategies. The following definitions are just summaries, so I suggest you go through the book for a better understanding.
Let’s explore each
- Common Closure Principle – It prompts to gather into components those classes that are likely to change for the same reasons. If two classes are so tightly bound, either physically or conceptually, that they always change together, then they belong in the same component. This minimizes the workload related to releasing, revalidating, and redeploying the software. This is the Single Responsibility Principle(SRP) restated for components.
- Common Reuse Principle – It helps us to decide which classes and modules should be placed into a component. It states that classes and modules that tend to be reused together belong in the same component. When one component uses another, it creates a dependency between each other. Perhaps the using component uses only one class within the used component, they still don’t weaken the dependency though. The using dependency still depends on the used component. It is also related to the Interface Segregation Principle.
- Dependency Inversion Principle – The rule states that outer layers (implementation details) can refer to inner layers (abstractions), but not the other way around. The inner layers should instead depend on interfaces. This provides a clear separation between ports, adapters, and application logic. Clean Architecture emphasizes this principle.
The Dependency Rule
The concentric circles represent different areas of software. In general, the further in you go, the higher level the software becomes. The outer circles are mechanisms. The inner circles are policies.
The overriding rule that makes this architecture work is the Dependency Rule:
“Source code dependencies must point only inward, toward higher-level policies.”
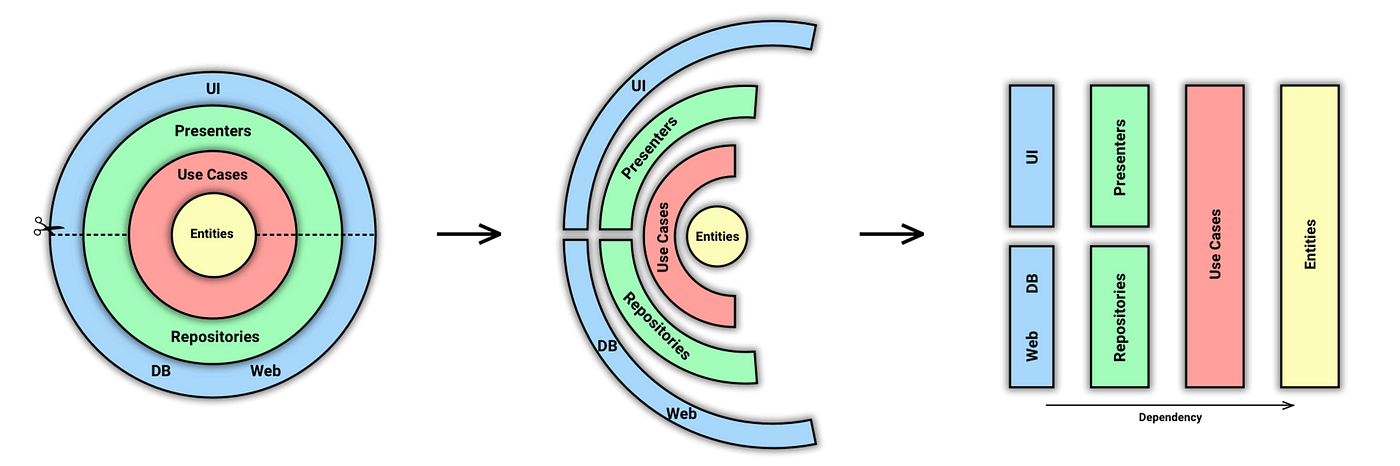
What does it mean?
Nothing in an inner circle can know anything at all about something in an outer circle. In particular, the name of something declared in an outer circle must not be mentioned by the code in an inner circle. That includes functions, classes, variables, or any other named software entity. i.e. Elements located in the Entities circle (the enterprise business rules) should not refer to any elements outside of it (such as application business rules, interface adapters, frameworks, and drivers).
As well as data formats used in an outer circle should not be used by an inner circle, especially if those formats are generated by a framework in an outer circle. The Clean architecture doesn’t want anything in an outer circle to impact the inner circles.

Let’s discuss each of these layers
Entities
- Encapsulate enterprise-wide critical business rules
- can be
- an object with methods
- a set of data structures and functions
- can be
- Could be used in many different applications in the enterprise
- Are the most general and high-level rules and the least likely to change when the external layer changes
Use Cases
- Encapsulate and implements application-specific business rules
- Orchestrate the flow of data to and from the entities and direct entities to use the critical business rules to achieve the goals of the use case
- Could not expect changes to affect the entities
- Could not be affected by changes in an external layer such as database, web, UI as well
- Could be changed only if the operation of the application changes

Interface Adapters
- Set of adapters
- Convert data from the format most convenient for the use cases and entities
- To the format most convenient for an external agency such as the database or the web
- Wholly contain the MVC architecture – the presenter, views, and controllers
Frameworks and Drivers
- Framework and tools such as
- Database
- Web framework
- Glue code that communicates to the next circle inward
- This layer contains all the details
- Keep these things on the outside where they do little harm
Only four layers?
There is no limit to keeping the architecture only to four layers. There are some cases you need more than just these four layers. However, the dependency rule always applies. Note the flow of control: It begins in the controller, moves through the use case, and then winds up executing in the presenter. Note also the source code dependencies: Each points inward toward the use cases. As you move inward, the level of abstraction and policy increases. The outermost circle consists of low-level concrete details. As you move inward, the software grows more abstract and encapsulates higher-level policies. The innermost circle is the most general and highest level.
Clean Architecture With Golang
Golang lends itself nicely to clean architecture. The interface/implementation pattern of Golang makes the dependency injection super easy. By defining small and clear interfaces and then implementing them in separate packages, the implementation details will end up nicely decoupled from core logic. It is quite simple to test each layer with popular library testify and mockery as well.
Let’s discuss clean architecture implementation in Golang with a simple authentication management service named AuthService. Hopefully, starting with this service will help you start as you mean to go on!
Quick Start
Once checking out the template, use the provided Makefile which includes a couple of targets for building, running, and tearing down the service.
- Run with Docker (starts MySQL, Redis, Mailhog)
make compose-up
- Tear-down the service
make compose-down
Project Structure
Full details are included in the project’s README, but some areas of particular interest include:
authsvc/authsvc.go
The entry point of the service performs object initialization and dependency injection starts the server and waits until it’s time to gracefully terminate.
authsvc/cfg/config.go
Configuration and logger initialization, before control is passed to main in authsvc/authsvc.go.
Now that we have the project structure as below:
├── cache <- cache database repository module (Redis) │ ├── auth.go <- refresh token store │ └── tokendb.go <- connection setup and managing connection instance ├── cfg <- project configuration module related on authsvc.json │ ├── config.go ├── db <- database repository module (MySQL) │ ├── authdb.go <- authdb connection setup and managing connection instance │ └── permission.go <- Permission store │ └── role.go <- Role store │ └── permission.go <- User store ├── email <- SMTP email client module │ ├── emailclient.go <- Use for sending new mail ├── log4u <- logging module; much like log4j has │ ├── log4u.go ├── render <- HTTP response renderer module │ └── jsonrenderer.go <- HTTP JSON response definition │ └── renderer.go <- Renderer interface ├── resource <- REST API endpoints's (resource) request handler │ └── auth.go <- Request handlers for auth resource e.g. /auth │ └── common.go <- resource utility │ └── errors.go <- HTTP request ERROR responses │ └── home.go <- / endpoint request handler │ └── protect.go <- Route protector │ └── token.go <- Request handlers for token resource e.g. /auth/token └── route <- Route builder module │ └── routebuilder.go ├── table <- Database entity/tables │ └── permission <- Permission table module consists of its definition and related DB operations │ └── table.go │ └── role <- Role table module consists of its definition and related DB operations | └── table.go │ └── user <- User table module consists of its definition and related DB operations | └── table.go └── token <- token service module │ └── service.go │ └── token.go └── uc <- Use cases │ └── adm <- Admin related use cases │ └── handler.go │ └── permission <- Permission related use cases | └── handler.go │ └── role <- Role related use cases | └── handler.go │ └── token <- Token related use cases | └── handler.go │ └── user <- User related use cases | └── handler.go │ └── common.go <- Use case utilities └── validator <- validator module with custom validators's tag e.g. `validPwd` │ └── validator.go └── authsvc.go <- entry point of the service └── authsvc.json <- service config └── go.mod <- list dependent packages └── go.sum <- list checksum of downloaded go modules and their dependencies └── version.go <- project versioning
Here, layer-to-package directory mapping
| Layer | Package Directory |
|---|---|
| Entities | token, table |
| Use Cases | adm, permission, role, token, user under uc directory |
| Interface Adapters | resource, render |
| Frameworks and Drivers | route, repository e.g. db, cache, email |
Dependency Injection
With the Dependency Inversion Principle, we’ll make use of dependency injection to enable a weak coupling between components and minimize direction dependencies.
- The Entities hold core business logic and know nothing about other layers. table, token, etc. packages are the entities in the AuthService.
- The UseCases can import entities but knows nothing about outer layers. user/handler in uc directory depends on entity e.g. table struct. It has no idea whether it’s being called by an HTTP request or CLI command.
- Controllers (e.g. resource package) can import usecase packages. They are the entry points to the application that often execute application services or commands.
- gorilla-mux route, db (MySQL), cache (Redis), SMTP (Mailhog) will operate on types found in UseCases and Entities layers.

To practice DIP in Golang, it’s best to understand Golang’s idea of “Accepts interfaces and return structs”.
Here is an example of DIP implementation in Golang where the Permission Table depends on the Store interface and db struct implements the store interface. By making it interface-dependent in this way, you can write code that is resistant to changes and easy to write tests.
package permission
type Permission struct {
ID int `json:"id"`
Name string `json:"name"`
Description string `json:"description"`
}
type Store interface {
ReadUserPermissions(string) ([]*Permission, error)
}
type Table struct {
store Store
}
func NewTable(s Store) *Table {
return &Table{s}
}
func (t *Table) ReadUserPermissions(login string) ([]*Permission, error) {
return t.store.ReadUserPermissions(login)
}
package db
import (
"database/sql"
"github.com/parthoshuvo/authsvc/table/permission"
)
// ReadUserPermissions fetches all authorized permissions for a user.
func (ad *AuthDB) ReadUserPermissions(login string) ([]*permission.Permission, error) {
return ad.readPermissions(func() (*sql.Rows, error) {
return ad.db.Query("call sp_read_user_permission(?)", login)
})
}
func (ad *AuthDB) readPermissions(dbReader func() (*sql.Rows, error)) ([]*permission.Permission, error) {
perms := make([]*permission.Permission, 0, 10)
rows, err := dbReader()
if err == sql.ErrNoRows {
return perms, nil
}
if err != nil {
return perms, err
}
defer rows.Close()
for rows.Next() {
var perm permission.Permission
if err := rows.Scan(
&perm.ID,
&perm.Name,
&perm.Description,
); err != nil {
return perms, err
}
perms = append(perms, &perm)
}
return perms, nil
}
Let’s look at the user login use case diagram to understand how the outer layers use the inner layer as a dependency. One thing to note is that the outer layer’s dependencies only point inward towards the inner layers.

Pros & Cons
| Pros | Cons |
|---|---|
| The architecture leans on top of a domain model | The learning curve of the architecture is not straightforward. People tend to mess up splitting responsibilities between layers which sometimes causes problems in the domain layer. |
| The application logic depends on nothing. However, everything depends on it. That implies directed coupling. | It sometimes causes indirection with the interfaces. |
| It is flexible to swap out any of the outer layers without impacting the inner layers’ logic. | It potentially takes time to implement |
| The architecture allows intrinsic testability. As the core part of the application does not depend on anything from the outer layer, it can be easily and quickly tested in isolation. |
Summary
Like all architectural concepts, Clean Architecture is a framework that you have to choose to adhere to throughout the life cycle of a piece of software. By complying with these rules is not difficult, and it will save you a lot of headaches going forward. However, It won’t physically prevent you from writing poor code. By separating the software into layers and leaning on the Dependency Rule, you will create a system that is intrinsically testable, with all the benefits that imply. Last but not least – A good architect pretends that the decision has not been made, and shapes the system in such a way that those decisions can still be deferred for as long as possible.
I hope the readers will find the benefits I highlighted in this article ????????.